SIMO framework contains program modules designed for forest management planning. It’s possible to combine different modules for different computation tasks. The properties of SIMO include easily modified control of planning computation and a set of model libraries that can be freely combined in the computation.
The different modules of the framework are data input, simulation, optimization and reporting. The modules are controlled with XML documents which contain the actual forest related information in the system. This enables the changes in the simulation logic without the need to resort to actual program code changes. The modules have been implemented mainly in Python. Some computationally heavy modules have been implemented in Cython and C.
During the data import the input data is converted to the form used internally in SIMO; this applies to the attribute names and units as well as the structure of the data. Simulation will produce different management alternatives for the forest area under planning. In optimization the alternative that best matches the goals and constraints of the planning is selected as the result of the planning. Reporting module is used to transfer data - input, simulation, or optimized - outside the framework. Different text and image based output formats are supported.
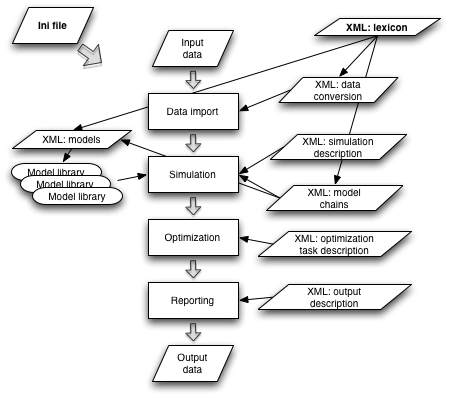
Figure 1. The components and the program flow of the SIMO framework
The data import module is able to transform the input data into the internal format of SIMO. Currently SIMO has support for two types of text files as input data. The data is either in one text file for all data levels or each data level; e.g., stand, tree species stratum, tree; is in its own text file and the data in different files is linked together with the use of identifiers.
The data conversion for data import is described in XML documents.
The starting point for data import is the lexicon XML document (Lexicon) which describes the data levels used in the computation; e.g. stand-stratum-tree; and the attributes the objects at each level can have. For each attribute the name, unit of measurement, minimum and maximum values and the description are given in the lexicon.
A conversion mapping describes the relationship between the lexicon and the input data (Data conversion). With the help of the conversion mapping the structure of the data as well as the attribute names and units are converted to the format understood by SIMO during the data import.
The simulator module contains the implementation for simulation of forest growth and alternative management regimes. The module consists of the simulator program code, collections of implementations of models describing the forest, and the XML documents used to describe the simulation task.
There is no default simulation in the implementation of the simulator. At the initialisation the simulator will read in the data and the content of the XML documents describing the simulation. Therefore, the simulation can be changed by changing the content of the XML documents. During the simulation the simulator will interpret the computation tasks defined in the XML model chains and applies those to the data. The simulator will call the models in the model libraries to compute new attribute values and will emit log messages to the user about the errors in the input data as well as in the model chains.
The simulation logic, attributes used and the details of the models are described in a set of XML documents. The basis is again set in the lexicon (Lexicon), which sets the way the forest is defined in the simulator. The top level description of a simulation is in a simulation XML document (Simulation). It contains the time periods used in the simulation as well as the parameter values and possible initial attribute values. Each simulation period definition also contains the model chains; i.e. the simulation logic; used in the simulation for that period (Model chain).
The models used in simulations are divided into two groups described by their own XML documents: the ones used to predict attribute values (Prediction model) and the ones describing the forestry operations (Operation model). These descriptions contain the model input attributes and parameters, output attributes as well as information about the restrictions for model usage and the data used to derive the model.
The cash flow XML documents (Cash flow) contain the income and costs associated with forestry operations.
The programmatic implementations of the prediction and operation models are collected into model libraries, which are shared program libraries (dll files on Windows, so files on Linux/Unix). The model libraries are dynamically attached to a simulation according to the content of the model chain, prediction- and operation model documents. Model libraries can be implemented either in C or in Python (Prediction model library, Operation model library).
The implemented prediction model library contains static and dynamic prediction model applicable to the forests of Finland. The models include both tree and stand level models. The implemented operation models include models for thinnings and final cuts as well as soil preparation, planting, natural regeneration, seedling tending models.
To make simulation with SIMO one has to complete a series of steps:
When creating a model library one has to take care that the variables used in the models match the ones defined in the lexicon (Lexicon). The models in the libraries must also be documented in the appropriate model description documents (Prediction model, Operation model).
The model chains decompose the simulation into a series of tasks. Each task is either fulfilled with a model or it is further divided into a series of subtasks. At the end each branch of a model chain ends into a model. The execution of each task in a model chain can be conditional.
The actual simulation is then composed by defining the set of model chains that it consists of. In addition different control parameters for the simulation are set: the start year of the simulation, the length of the simulation period, the number of periods, possible stopping conditions for the simulation and a host of other parameters including the names of the attributes that should be stored into the result database during the simulation. Should one want to change the names of the data levels used in the simulation, it must be done at this phase by modifying the lexicon, model, model chain and simulation xml documents.
The optimization module contains tools for solving an optimization task. In the optimization the combination of the all simulated alternatives is selected which best fulfills the goals and constraints of the optimization task. The solution is stored in a database for later reporting.
The implementation of the optimization module contains currently two heuristic optimization algorithms and an interface to a linear programming optimization package J.
The optimization task is described in an XML document containing definitions for the goal and the constraints (Optimization).
The role of the reporting module is to produce output from the input, simulated and optimized data. The output can be generated for individual computation units; e.g., stands, or for the whole planning area.
Supported data result text formats are inlined, by_level and smt. For these formats the output attributes are defined in an XML document (Output constraint). Format smt is meant to be used for single data level data reporting and it conforms to the structure used by the MELA planning system by the Finnish Forest Research Institute.
For aggregating values over time and location, there is an output format aggregation which outputs aggregated values (sum, mean, max, min) for attributes. The aggregation rules and output options are defined in an XML document (Aggregation definition).
Very close to aggregation report format is expression, which instead of aggration over simulation units, reports values by simulation unit (see Expression definition)
The forestry operation results are reported with the format operation_result.
branching_graph format outputs dot text files that can be converted into images with the Graphviz program. Dot files are generated per computation unit and they describe the branching of the simulation results as well as the forestry operation causing each branch generation.
